
There’s a gap in how people talk about building AI agents. Most tutorials show you getting an LLM to respond. That part is easy. What nobody tells you about is everything that happens after.
When we started building Jottly and our first custom agent projects, we thought agent development would follow a familiar pattern: call the API, get a response, done. But real production agents are fundamentally different. They need to act reliably at scale, handle streaming without breaking the frontend, maintain context across dozens of conversations, route between models intelligently, recover from failures, and stay safe.
We kept rebuilding the same infrastructure. Over and over.
The Discovery
Around six months into building Jottly, we had a working agent. It could transcribe lectures, extract deadlines, answer questions about notes. But the actual product code, the machinery making that agent reliable, started to feel redundant. We had recursive tool loops. We had context management. We had streaming handlers. We had safety layers.
Then we started taking on custom agent projects for other companies. And we started rebuilding all of it again.
That’s when it clicked: the gap between a demo agent and a production agent isn’t small. It’s massive. And it’s not specific to any one product. Anyone building AI agents in production hits these same walls.
What Actually Matters in Production
After going through this cycle twice, we extracted the core problems into SAGE. Here’s what we learned needs to happen:
The agentic loop is non-obvious. It’s not “call the API once and get back a final answer.” It’s recursive. The model calls tools, you execute them, you feed results back, the model calls more tools or says it’s done. But here’s the key insight we discovered: when the model requests multiple tools, you should execute them in parallel. Most people build this sequentially. The model naturally orchestrates concurrency by deciding how many tools to call per turn. You don’t need a separate orchestration layer. The model is already the scheduler.
Context management is where 70% of the hard work lives. You can’t just throw messages into a sliding window and hope it works. In real conversations, agents fail because they lose context or the window grows too large. SAGE runs a multi-stage pipeline before every LLM call: working memory injects relevant facts and user preferences into the system prompt, a sliding window manages recent messages with tool-call integrity (never splitting a tool call from its result, even under truncation pressure), an LLM summarizer compresses older conversation history in the background without blocking the response, and error memory surfaces lessons from past mistakes. This runs automatically. Without it, agents degrade badly over time.
Agents need to learn from their mistakes. This is the one nobody talks about. Most agent frameworks treat every conversation as a blank slate. If the agent makes a mistake, it has no mechanism to avoid making the same mistake next time.
SAGE has an error memory system that changes this fundamentally. Every time a tool call fails or returns an error, the system captures it, extracts a lesson using deterministic pattern matching (no expensive LLM calls), and stores it with a confidence score. When the same error pattern recurs, its confidence increases. Errors that were transient naturally decay over time through exponential half-life, but established patterns persist. Before every LLM call, the highest-confidence lessons are injected directly into the agent’s system prompt.
The result: agents get more reliable the more they run. A mistake made on Monday doesn’t happen again on Tuesday. An error pattern that shows up across five different conversations becomes a deeply embedded lesson the agent will actively avoid. This is scoped per project, so different deployments build their own independent error knowledge.
Working memory makes agents feel intelligent, not just responsive. Most chatbots forget everything between conversations. SAGE agents don’t. The working memory system automatically extracts facts, preferences, and context from every conversation and categorizes them by type and persistence. Facts the user explicitly states get permanent, high-confidence storage. Inferred patterns get shorter-lived, lower-confidence entries. Everything is scored across seven factors (semantic similarity, recency, access frequency, confidence, entity matching, importance, and persistence level) when retrieved.
The practical impact: an agent that’s handled 50 conversations with a client doesn’t feel like it’s meeting them for the first time on conversation 51. It remembers their preferences, their terminology, their past decisions. Memories that prove useful get reinforced automatically. Memories that stop being relevant decay naturally.
Provider abstraction is actually critical. Every model provider returns streaming responses differently. If your agent code depends on any one format, you’re stuck. You can’t swap models without rewriting your streaming layer. You can’t experiment with faster or cheaper alternatives. We normalized everything into a single event interface. The agent loop doesn’t know which provider it’s talking to. This simple boundary unlocked the ability to route between models mid-conversation based on task complexity, cost, or latency requirements.
Safety shouldn’t be bolted on. Injection detection, PII redaction, content filtering, tool input validation. These need to be composable from the start, not afterthoughts. Not every use case needs everything. But every production use case needs something.
How It All Fits Together
This is a simplified view of how a request flows through SAGE:
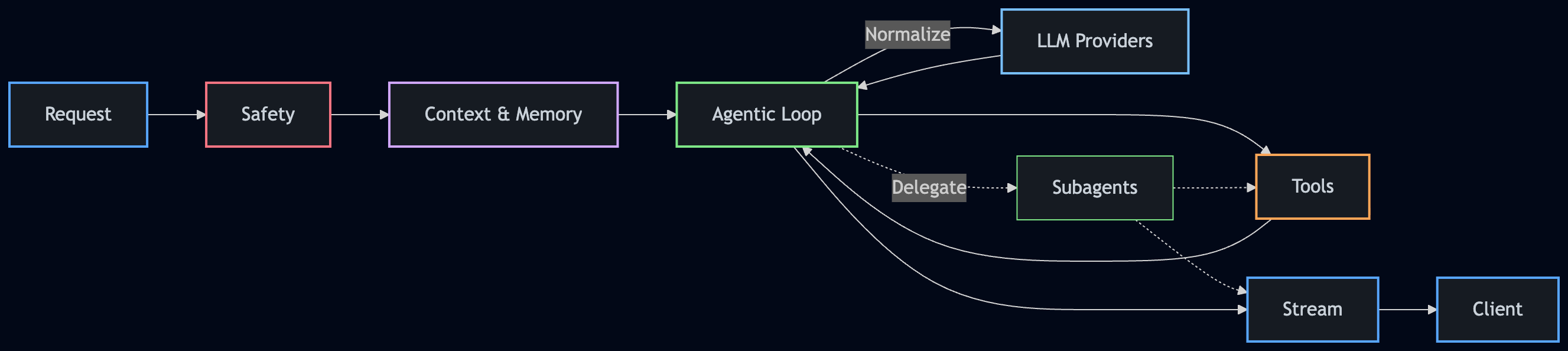
A request enters through safety layers first. Context and memory are assembled before the agentic loop begins. The loop communicates with LLM providers through a normalized interface, executes tools (in parallel when possible), and can delegate to subagents for complex tasks. Everything streams back to the client in real time.
The key detail here: subagents write to the same stream as their parent, tagged and differentiated, so the client sees a single coherent response even when multiple agents are working underneath.
Why This Matters
SAGE is the engine that now powers everything we build at NeuroQuest Labs. Jottly runs on it. Every custom agent we build for clients runs on it. When a company comes to us needing an autonomous support agent, a document processing system, or a knowledge assistant, we don’t start from scratch. We start from SAGE and build up.
That’s the advantage of solving these problems once and solving them well. Every layer is pluggable. We can swap providers mid-conversation. We can build hierarchical agents where subagents write to the same stream as their parent, tagged and streamed in real time. We can compose safety layers however the use case demands. And when we improve SAGE, every product built on top of it gets better automatically.
What We Learned by Shipping This
Building agents isn’t about being clever with prompts. That’s the fun part, but it’s not the hard part. The hard part is everything else.
The hard part is swapping between models without rewriting code. It’s knowing why an agent looped and preventing it from happening again. It’s surfacing streaming responses to the frontend without the agent being frozen mid-thought. It’s keeping context coherent across 50 conversations. It’s building agents that genuinely improve with use, not just respond.
Once you solve for these problems, something interesting happens: agents become reliable enough to actually use. Jottly’s agent doesn’t feel like a demo. Our custom agents don’t feel like toys. They work because the infrastructure beneath them handles the weight.
That’s why SAGE exists. It’s the engine we kept rebuilding, extracted into the foundation that powers everything we ship.
If you’re thinking about building agents into your product and don’t want to spend months solving infrastructure problems, that’s exactly what our Custom Agents division does. We build production-grade agents for companies, powered by SAGE, so you get all of this out of the box.
We’re always looking for interesting problems. If you need agents that actually work in production, not demos, reach out. We’d love to hear what you’re building.